Recognize and Synthesize Speech
To build software that can interpret audible speech and respond appropriately, you can use the Speech cognitive service, which provides a simple way to transcribe spoken language into text and vice-versa.
For example, suppose you want to create a smart device that can respond verbally to spoken questions, such as “What time is it?”
Create a Speech resource
Let’s start by creating a Speech resource in your Azure subscription:
- In another browser tab, open the Azure portal at https://portal.azure.com, signing in with your Microsoft account.
- Click the +Create a resource button, search for Speech, and create a Speech resource with the following settings:
- Name: Enter a unique name.
- Subscription: Your Azure subscription.
- Location: Choose any available region
- Pricing tier: Free F0
- Resource group: Select an existing resource group or create a new one.
- Review and create the resource, and wait for deployment to complete. Then go to the deployed resource.
- View the Keys and Endpoint page for your Speech resource. You will need the location/region and keys to connect from client applications.
Use a cloud shell
To test the capabilities of the Custom Vision service to detect objects in images, we’ll use a simple command-line application that runs in the cloud shell.
Note: For this lab, you will test out an application in a cloud shell environment. When you build your own application, you can use an environment of your choice.
-
Click the Activate Sandbox button at the top of the page. This starts a Cloud Shell instance to your right, as shown here. You may be prompted to review permissions. Click Accept.
-
When you open the cloud shell, you will need to change the type of shell you are using from Bash to PowerShell. Type in pwsh and press enter.
pwsh
Configure and run a client application
Now that you have a cloud shell environment, you can run a simple client application that uses the Computer Vision service to analyze an image.
-
In the command shell, enter the following command to download the sample application.
git clone https://github.com/GraemeMalcolm/ai-stuff ai-900 -
The files are downloaded to a folder named ai-900. Now we want to see all of the files in your cloud shell storage and work with them. Type the following command into the shell:
code .Notice how this opens up an editor.
-
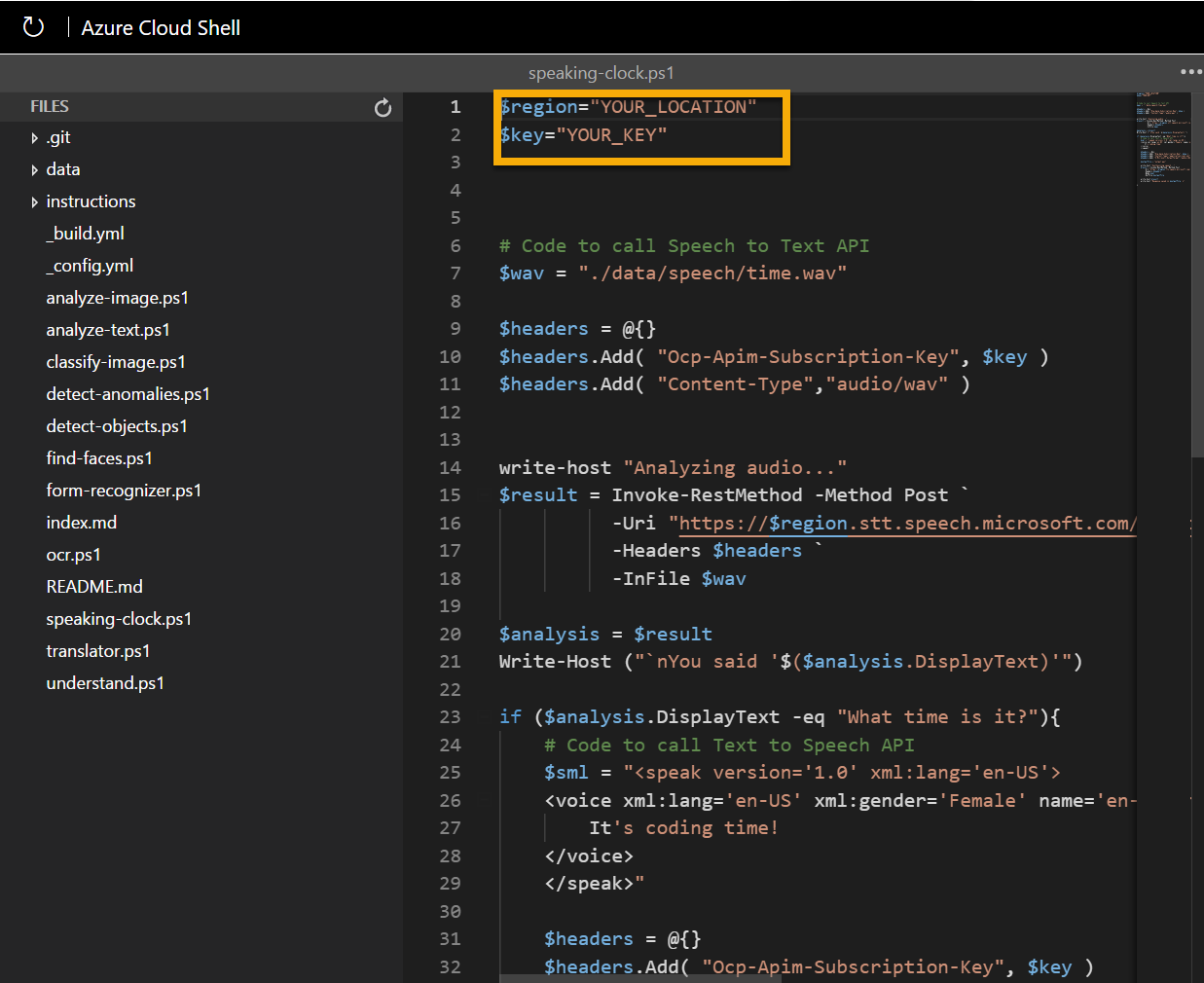
In the Files pane on the left, expand ai-900 and select speaking-clock.ps1. This file contains some code that uses the Speech service to recognize and synthesize speech:
-
Don’t worry too much about the details of the code, the important thing is that it needs the region/location and either of the keys for your Speech resource. Copy these from the Keys and Endpoints page for your resource (which should still be in the top area of the browser) and paste them into the code editor, replacing the YOUR_LOCATION and YOUR_KEY placeholder values respectively.
Tip: You may need to use the separator bar to adjust the screen area as you work with the Keys and Endpoint and Editor panes.
After pasting the endpoint and key values, the first two lines of code should look similar to this:
$region="eastus" $key="1a2b3c4d5e6f7g8h9i0j...." -
At the top right of the editor pane, use the … button to open the menu and select Save to save your changes. Then open the menu again and select Close Editor.
The sample client application will use your Speech service to transcribe spoken input and synthesize an appropriate spoken response. A real application would accept the input from a microphone and send the response to a speaker, but in this simple example, we’ll use pre-recorded input in an audio file and save the response as another audio file.
Use the audio player below to hear the input audio the application will process:
-
In the PowerShell pane, enter the following command to run the code:
cd ai-900 .\speaking-clock.ps1 -
Review the output, which should have successfully recognized the text “What time is it?” and saved an appropriate response in a file named output.wav.
Use the following audio player to hear the spoken output generated by the application:
Learn more
This simple app shows only some of the capabilities of the Speech service. To learn more about what you can do with this service, see the Speech page.